
Lo que pasa cuando una plataforma dirigida por YAML se encuentra con la realidad de producción: scheduling, idempotencia, locks, drift y la disciplina de convertir cada cicatriz en un contrato.
Abrís una llave y sale agua. Los primeros tres posts de esta serie fueron sobre construir la infraestructura detrás de esa llave: una plataforma de ingesta dirigida por YAML para una capa Bronze de Lakehouse: un motor fijo más N archivos de configuración de entidades, metadato que gobierna metadato, un scheduler que convierte la frescura en un contrato. El diseño es sólido. Los tests pasan. El inspector firma.
Después llega el invierno.
Las tuberías se congelan. Una junta se raja. Alguien aguas arriba cierra una válvula que nadie documentó. Una actualización del runtime de Spark rompe silenciosamente fechas que venían cargando bien por dos años. Una carga termina en PartialSuccess y ahora tenés medio día de datos sin una forma limpia de saber cuál mitad. El Post 3 terminó con una advertencia: un proceso crashea a las 2:00 am sin liberar su lock y bloquea silenciosamente un dominio entero hasta que alguien lo nota a las 9:00 am. Este post empieza ahí, y agrega tres modos de falla más que llegaron de la misma manera: sin aviso, en producción, un jueves.
Nada de esto estaba en el diagrama. Todo apareció en producción.
Este post es sobre cuatro cicatrices de implementaciones reales de Lakehouse, las que aparecen independientemente de la fuente, la escala o el equipo. No porque las cicatrices sean inteligentes (no lo son). Sino porque el test de una plataforma dirigida por metadatos no es si las evita. Es si cada una vuelve al contrato (un campo nuevo de YAML, una nueva estrategia de partición, una columna de auditoría, un runbook) en lugar de un parche aislado enterrado en un notebook.
Una arquitectura sin cicatrices no es buen diseño. Es poco uso. Lo aburrido se gana, no se diseña, y este post es sobre el ganarlo.
Cicatriz #1: Cuando las versiones de Spark no se ponen de acuerdo con las fechas
El síntoma. Una carga que venía corriendo sin incidentes por meses empieza a fallar:
INCONSISTENT_BEHAVIOR_CROSS_VERSION.READ_ANCIENT_DATETIME
La causa. Los archivos Parquet escritos por Spark 2.x usan INT96 para timestamps. Spark 3.x (la versión del runtime de Fabric) aplica el calendario gregoriano proléptico estrictamente: las columnas Date rechazan valores anteriores al 1582-10-15 (el límite de la reforma del calendario gregoriano); las columnas Timestamp rechazan valores anteriores al 1900-01-01. Qué umbral se dispara depende de cómo está almacenada la columna. Algunos archivos fuente tenían fechas placeholder: 1753-01-01, 1900-01-01, usadas por el sistema upstream para representar «desconocido». Siempre habían estado ahí. Cada runtime anterior había estado bien con ellas. Después el runtime se actualizó.
El arreglo tentador. Parchear el notebook. Atrapar la excepción, nullificar las columnas problemáticas, seguir. Cuarenta y cinco minutos de trabajo, problema resuelto.
El arreglo que elegimos. Un nuevo campo directo en el YAML de la entidad, declarado a nivel de entidad y aplicado cuando el motor lee archivos Parquet previamente staged en storage:
parquet_date_fix:
enabled: true
columns: ["ACTDATE", "CREATEDATE"]
cutoff_date: "1900-01-01"
action: "NULL"
El workaround ahora está declarado, no oculto. Cada YAML que hereda este problema lo declara explícitamente. Un ingeniero nuevo leyendo Finance_LegacySystem.yml ve parquet_date_fix: enabled: true y entiende de inmediato que esta fuente tiene una incompatibilidad conocida. No hay ningún try/except enterrado en un notebook para que alguien se tropiece en seis meses.
El gotcha dentro del arreglo. En YAML, action: NULL sin comillas se parsea como null de Python. El motor lo lee como None y lanza action 'None' not implemented. La forma correcta es action: "NULL", un string entre comillas. Un par de comillas faltante, sintaxis YAML perfectamente válida, comportamiento completamente incorrecto. El contrato tiene sus propias reglas de tipo, y no siempre son obvias.
Qué pasa con los valores nullificados. El motor registra cada valor nullificado en una tabla de auditoría: RunID, columna, valor original, identificador de fila. Si alguien después pregunta si CREATEDATE realmente fue nullificado para un registro específico, la respuesta es una consulta, no un encogimiento de hombros. El cutoff maneja dos categorías: valores rechazados por Spark (columnas Date pre-1582, columnas Timestamp pre-1900) y los propios sentinelas del sistema fuente: 1900-01-01 usado acá para representar «fecha desconocida». Ambas caen en la misma tabla de auditoría con el mismo RunID. El único riesgo: si cutoff_date se establece demasiado alto (2000-01-01 en lugar de 1900-01-01), fechas de negocio legítimas del siglo XX se nullifican. El umbral es un juicio que necesita aval de alguien que sabe qué significan esas fechas.
La lección. Cada workaround de compatibilidad termina en el contrato. El motor no acumula casos especiales para fuentes individuales. El YAML crece un flag que dice «esta fuente tiene este problema conocido, aplicar este tratamiento conocido, registrarlo de esta manera». Cuando el sistema upstream finalmente se arregla, cambiar enabled: false es un PR de una línea y el workaround desaparece limpiamente.
Visible, reversible, auditable. Tres propiedades que los parches en notebooks nunca tienen.
Un detalle que cierra el loop con el Post 2: agregar parquet_date_fix requirió actualizar el schema de Yamale. El campo no existía cuando se escribió el archivo .schema, y cualquier entidad que lo desplegara habría fallado la validación L4 antes de llegar al motor. Un PR agregó parquet_date_fix como un bloque opcional al archivo de schema; template_version incrementó de "1.0" a "1.1". YAML tolera secciones nuevas con gracia: un notebook que no sabe de parquet_date_fix lo ignora sin problema. Pero template_version no es sobre tolerancia de YAML; es sobre asegurar que el motor, el schema de Yamale y los archivos YAML estén todos apuntando al mismo contrato. Un bump de versión hace visible el cambio en el audit trail y le da al motor un hook para aplicar lógica específica de versión cuando sea necesario. Las entidades que necesitaban el arreglo lo declararon; las que no quedaron intactas. La plataforma absorbió un nuevo requerimiento con exactamente la fricción que el Post 2 diseñó: un PR de schema, validación antes de cada despliegue.
El Runbook DATE-FIX-01 cubre detección, activación del flag, auditoría de impacto y criterios de retiro. Ver Post 5 para la disciplina de runbooks.
Cicatriz #2: Fallas parciales e idempotencia por SnapshotDate
El síntoma. Un batch de varias docenas de entidades termina con la mayoría exitosas y unas pocas fallando: un blip de red, un timeout de fuente, un error intermitente de driver. Estado del pipeline: PartialSuccess.
Por qué esto es peor que una falla total. La falla total es limpia. Reintentás, te recuperás. La falla parcial te deja con medio día de datos cargados. Ahora tenés que saber qué entidades fallaron, cuáles tuvieron éxito, si reintentar cargaría doble a las exitosas o solo recogería las fallidas. La respuesta depende de si tu pipeline fue diseñado para esta pregunta. La mayoría no.
El patrón que nos salvó: idempotencia por SnapshotDate. Cada ingesta se particiona por SnapshotDate. Una re-corrida para el mismo día reemplaza esa partición: no la agrega, no la mergea, no la deduplica. Sobreescribe. Volver a correr todo el batch es seguro porque los éxitos se reescriben de forma idéntica y los fallidos se reintentan, siempre que la fuente produzca los mismos datos en el reintento. Eso se cumple para la mayoría de las extracciones batch; no se cumple para fuentes con ventanas rolling o APIs stateful, donde un reintento a mitad de ventana puede traer datos distintos a la corrida original. Sin procedimiento de rollback, sin orquestación «saltate estos, incluí aquellos»:
df.write.mode("overwrite") \
.option("partitionOverwriteMode", "dynamic") \
.partitionBy("SnapshotDate") \
.saveAsTable(...)
El diagnóstico sigue siendo simple. La tabla de control notebooklog registra el RunID, estado, timestamp y error de cada entidad. Una consulta te dice cuáles tres entidades fallaron y por qué. No tenés que escarbar en los logs nativos de pipeline de Fabric: tus propias tablas de control fueron construidas exactamente para esta pregunta.
La lección. La idempotencia no es una feature que agregás después. Es una decisión de partition-key que tomás el día uno. Hacelo bien y las fallas parciales se convierten en problemas de retry (baratos). Hacelo mal y se convierten en problemas de consistencia (caros). La diferencia entre ambos es aproximadamente la diferencia entre «volvé a correr el pipeline» y «convocá una reunión».
El caso borde honesto. La sobreescritura a nivel de partición es segura cuando las entidades escriben limpiamente o fallan limpiamente. Cuando una entidad escribe parcialmente (escribió algunas filas, crasheó a mitad de partición, dejó un estado inconsistente), la garantía de sobreescritura depende de que la partición esté suficientemente completa para reemplazarse. En la práctica esto es raro, pero es el escenario donde la idempotencia pasa de «retry gratis» a «limpieza manual primero, después retry». La resolución sigue siendo un DELETE WHERE SnapshotDate = '{date}' en la entidad afectada y una segunda corrida (no un rollback, no una operación de merge), pero es un paso manual, no cero.
El Runbook IDEMPOTENCY-01 cubre el diagnóstico de PartialSuccess, el procedimiento de re-corrida segura y el camino de limpieza manual para fallas a mitad de partición.
Cicatriz #3: Cuando el guard lock sobrevive al guard
El síntoma. El scheduler se niega a disparar una carga. control.SchedulerLocks muestra que la carga está bloqueada. El proceso que adquirió el lock crasheó hace dos horas. El lock sigue ahí.
Para qué existen los locks. Dos corridas del scheduler no pueden tocar la misma carga simultáneamente. Si una carga está en plena ejecución cuando el scheduler evalúa de nuevo, pasan cosas malas: escrituras duplicadas, actualizaciones de metadato en carrera, batches huérfanos. El lock es una garantía de escritor único. El Post 3 introdujo esta consecuencia como una propiedad inherente del diseño del scheduler.
control.SchedulerLocks tiene una fila por carga:
-- control.SchedulerLocks (one row per CargaKey)
CargaKey STRING -- {Country}_{Domain}_{Source}
IsLocked BOOLEAN -- true while load is running
LockAcquiredTime TIMESTAMP
LockOwnerRunID STRING -- PipelineRunID holding the lock
LockOwnerExecutionID STRING -- ExecutionID holding the lock
LockReleasedTime TIMESTAMP -- null while locked
ReleasedReason STRING -- null while locked; required on manual release
LastUpdated TIMESTAMP
Por qué el lock sobrevivió al escritor. El proceso no hizo la limpieza limpiamente: interrupción de red, timeout de sesión de Fabric, desalojo de cluster. El código de limpieza estaba en un bloque finally que nunca corrió. El lock ahora es un zombie.
La salida de emergencia. Antes de ejecutar, confirmá en el monitor del pipeline que no hay ninguna ejecución activa actualmente para esta carga. Liberar un lock mientras el proceso todavía está corriendo crea exactamente la condición de carrera que el lock debía prevenir.
UPDATE control.SchedulerLocks
SET IsLocked = false,
LockReleasedTime = current_timestamp(),
ReleasedReason = 'Manual release: RunID X failed with network timeout'
WHERE CargaKey = '{key}'
AND IsLocked = true
AND LockOwnerRunID = '{RunID}';
El filtro LockOwnerRunID asegura que estés liberando el lock específico que diagnosticaste, no un lock que otro proceso puede haber adquirido entre tu diagnóstico y tu actualización.
Esto es deliberadamente manual. Deliberadamente ruidoso. ReleasedReason es requerido, no opcional: si alguien desbloquea una carga, dice por qué. Seis meses después, cuando alguien consulta el historial de locks, la razón está ahí en texto plano.
¿Cuánto tiempo antes de que un lock sea un zombie? En nuestro escenario, cuatro horas fue el umbral práctico: si un lock se ha mantenido por más tiempo que eso sin ninguna ejecución activa visible en el monitor del pipeline, no se liberó limpiamente. Por debajo de cuatro horas, el proceso podría todavía estar corriendo con un volumen inusual. El umbral es un parámetro del scheduler: calibralo contra tu carga más lenta normal. El principio de liberación manual con un audit trail no es un parámetro.
¿Por qué no auto-liberar con un timeout? Lo consideramos. El riesgo: una carga corre legítimamente por más tiempo (volumen inusual, fuente lenta), el timeout se dispara, el lock se libera, el scheduler se dispara de nuevo. Ahora tenés dos cargas concurrentes. La liberación manual con un humano en el loop es más lenta, pero la frecuencia de locks zombies (rara, no rutinaria) hace que el costo sea aceptable. Para algo que pasa una vez al mes, la certeza vale el paso extra.
La lección. Los locks distribuidos necesitan salidas de emergencia explícitas, y la salida de emergencia tiene que dejar un audit trail. Un desbloqueo sin razón es deuda técnica con timestamp. Un desbloqueo con razón es una entrada de log que un ingeniero futuro puede usar para decidir si el lock original fue adquirido correctamente en primer lugar.
El Runbook LOCK-01 cubre el diagnóstico de lock zombie (umbral de 4h), verificación de proceso activo y liberación manual con ReleasedReason requerido.
Cicatriz #4: El YAML en Git no es el YAML que está corriendo
El síntoma. Se mergeó un PR que modificó Sales_Salesforce.yml. El pipeline corrió esa noche. El cambio no tomó efecto. Todos revisaron el diff, aprobaron el PR, confirmaron el merge, y el pipeline se comportó como si el cambio nunca hubiera existido.
La causa. El YAML en Git fue actualizado. El YAML desplegado al Lakehouse (el que el motor lee realmente en runtime) era el viejo. El flujo GitOps se detuvo en «merge». El despliegue era manual. Y los despliegues manuales son, eventualmente, olvidados.
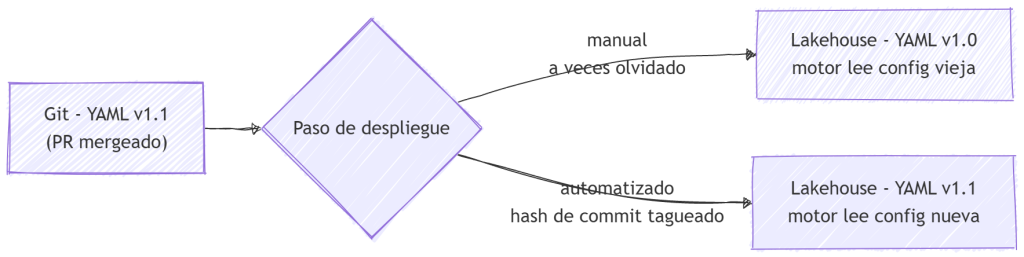
Por qué el despliegue no estuvo automatizado desde el día uno. Debería haberlo estado. La respuesta honesta: otras prioridades, y «merge → subida manual» funcionó para la abrumadora mayoría de los casos. La cicatriz #4 es sobre las excepciones. El Post 1 establece el despliegue automatizado como un principio de inicio («El Lakehouse contiene artefactos desplegados, no editables») porque lo aprendimos exactamente de esta cicatriz.
El arreglo: un proceso antes que una herramienta.
- PR con el cambio de YAML.
- Validación Yamale pre-despliegue (del Post 2).
- Subida manual a
Lh_Metadatos/Files/config/con un checklist de despliegue. - Smoke test con
entities_filter: el motor soporta correr un subconjunto antes de comprometerse a una carga completa:entities_filter = ["Opportunities"] # solo esta entidad # después de validar: entities_filter = None # todas las entidades (None de Python, no el string "none") - Corrida completa solo después de que la corrida filtrada confirme que el cambio tomó efecto.
- El Runbook CFG-01 documenta todo esto.
Más tarde, el despliegue se automatizó: el merge del PR dispara una copia automática a la carpeta del Lakehouse, con el hash del commit tagueado en el archivo desplegado. Pero el proceso llegó primero. Las herramientas hacen cumplir el proceso; no lo crean.
El paralelo null/string que vale notar. La cicatriz #1 enseñó que action: NULL en YAML se parsea como None de Python. Acá: entities_filter = None (null de Python) es correcto; el string "none" es incorrecto, en la dirección opuesta. La misma confusión de tipos aparece en ambas capas. Tanto el YAML como el motor tienen reglas de sintaxis que parecen obvias después de que las rompés una vez.
La lección, y la más difícil. «Versionado en Git» no es lo mismo que «corriendo en producción» hasta que hay un mecanismo de despliegue al que podés apuntar. GitOps sin CD crea una categoría de drift que es más difícil de detectar que el drift de ambiente, porque ambos lados se ven correctos individualmente. La versión en Git es correcta. La versión desplegada es correcta: resulta ser la anterior. Cuando algo se rompe, la primera pregunta («¿el YAML que estoy mirando es el que corrió?») no puede responderse con confianza. El arreglo es aburrido: un script de despliegue, un tag de hash de commit en el archivo de configuración. El costo de no tenerlo es enorme.
El drift de configuración tiene más de una dimensión. La brecha desplegado/Git es la más visible, pero hay otras: entidades habilitadas en YAML sin ejecución reciente, entidades habilitadas sin tabla Delta en el Lakehouse. Ambas pueden detectarse con un simple cross-reference: hacer join de los YAMLs desplegados contra notebooklog filtrado a los últimos N días para encontrar entidades configuradas que nunca corrieron; hacer join contra el catálogo del Lakehouse para encontrar entidades configuradas sin tabla Delta. Las tres comparten la misma raíz: el YAML describe un mundo que no es el que realmente está corriendo. El patrón completo de auditoría de consistencia es material para el Post 6 (Metadato vivo).
El Runbook CFG-01 cubre validación pre-despliegue, smoke test con entities_filter, checklist de despliegue y los triggers para una auditoría de consistencia.
Las cicatrices como maestras
Cada cicatriz arriba empezó como un incidente de producción. Cada una terminó como un campo de YAML, una estrategia de partición, una columna de auditoría o una entrada en un runbook. Ninguna aparece en los diagramas de arquitectura. Todas son load-bearing.
El Post 1 dijo que Bronze debería ser aburrido. El Post 2 dijo que el metadato gobierna el metadato. El Post 3 dijo que el scheduler convierte la frescura en un contrato. Este post agrega uno más: cada cicatriz es un artefacto o folklore. Un artefacto está documentado, versionado, reversible: un flag de YAML, una estrategia de partición, un runbook. El folklore es algo que el ingeniero senior sabe y el junior aprende rompiendo cosas a las 3:00 am.
Una arquitectura sin cicatrices no es una que lo hizo todo bien en el primer intento. Es una que todavía no ha sido estresada. En el momento en que se encuentra con carga real, cambios upstream o una sorpresa del runtime que no planeó, empezará a acumular cicatrices como todos los sistemas que corren en producción. La única pregunta es cuáles.
Los japoneses tienen un nombre para esto: kintsugi. Cuando una pieza de cerámica se rompe, no se tira. Tampoco se repara con adhesivo invisible para imitar lo que era antes. El maestro la repara con oro. La grieta no desaparece — se vuelve la parte más visible, la más valiosa. La filosofía detrás es simple y directa: la ruptura y la reparación son parte de la historia del objeto, no algo que esconder o disimular. El objeto roto y reparado con oro es más honesto que el que llegó intacto. Lleva su historia en la superficie.
Una plataforma de datos no es diferente. El parche enterrado en el notebook imita lo intacto: la grieta existe pero nadie la ve. parquet_date_fix: enabled: true en el YAML es el oro — la incompatibilidad es visible, declarada, parte del contrato. El Runbook LOCK-01 es el oro — la cicatriz tiene nombre, tiene procedimiento, tiene audit trail. No son vergüenzas de ingeniería. Son evidencia de un sistema que aprendió algo en producción y lo llevó a la superficie.
Los artefactos no se crean solos. El campo de YAML captura el workaround. La estrategia de partición captura el modo de falla. El runbook captura qué debería hacer un humano cuando pasa de nuevo: qué verificar cuando el lock está trabado, cuando el despliegue no se propagó, cuando las fechas de una columna dejaron de parsear. El contrato captura qué debería hacer el motor de forma diferente. Ambos importan. Ninguno sobrevive a menos que alguien lo escriba.
DAMA DMBOK lo establece en ambos extremos del stack: «todos los cambios deben ser scripteados» (Cap. 6 Data Storage and Operations, §4.3, p. 210) y «todos los cambios deberían pasar por un proceso de gestión de cambios gobernado» (Cap. 13 Data Quality, p. 470). Cuatro cicatrices de producción después, la razón no es teórica.
Qué viene
Post 5. Runbooks como infraestructura: Cada cicatriz arriba dejó no solo un campo de YAML sino una instrucción para el humano: qué hace el ingeniero de guardia cuando pasa de nuevo a las 3:00 am. Esas instrucciones son infraestructura, no documentación; versionadas junto al motor, testeadas por el test de las 3:00 am, referenciadas por IDs estables desde las tablas de control que alarmaron al ingeniero en primer lugar. Por qué los runbooks en Confluence se pudren, por qué los runbooks en Git no, y qué separa un runbook que le podés dar a alguien sin contexto de uno que solo puede ejecutar el autor.
Post 6. Metadato vivo: Cada cicatriz en este post generó datos. parquet_date_fix registra los valores nullificados. SchedulerLocks registra las razones de desbloqueo. notebooklog captura cada falla parcial. Las tablas de control están llenas, pero si nadie las lee, son metadato muerto. Cómo los logs se vuelven reportes, los reportes se vuelven decisiones, y tres audiencias distintas (ops, calidad, gobierno) terminan consumiendo los mismos datos subyacentes para tres propósitos diferentes.
← Anterior: El Calendarizador | → Siguiente: Runbooks como infraestructura
Este es el cuarto post de la serie «Ingesta dirigida por metadatos en YAML». Los patrones descritos evolucionaron a través de varias implementaciones de Lakehouse empresariales y son agnósticos a la plataforma, aunque nuestra plataforma de referencia es Microsoft Fabric.
Deja una respuesta